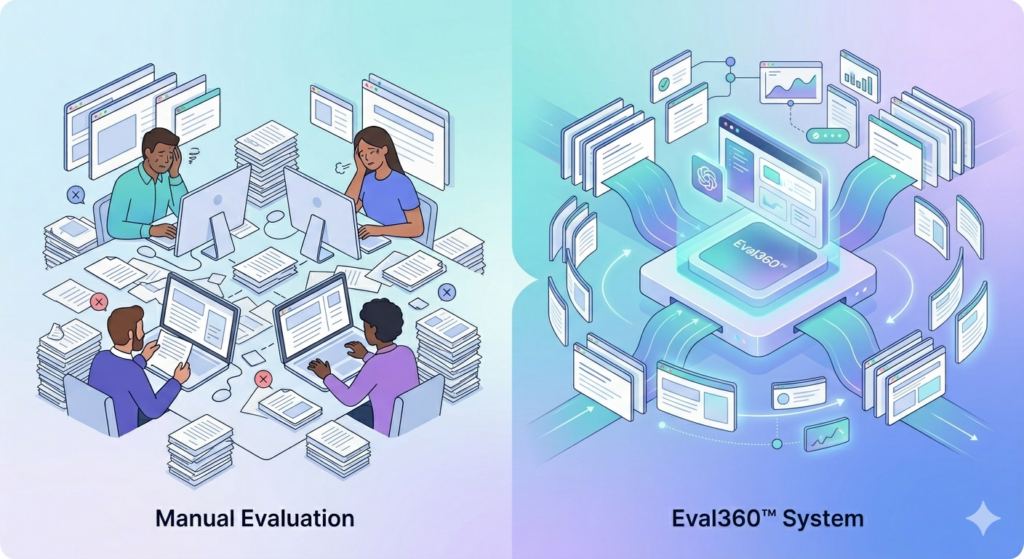
Human evaluation is not scalable because it requires significant time, cost, and manual effort to review AI-generated outputs. As AI systems produce large volumes of responses, it becomes impractical for humans to evaluate everything consistently and quickly.
While human judgment provides high-quality feedback, it cannot keep up with the speed and scale of modern AI systems.
What human evaluation involves
Human evaluation means reviewing AI outputs to check:
- Accuracy
- Relevance
- Safety
- Quality
This process often requires domain experts, especially in fields like legal, finance, or healthcare.
Key reasons human evaluation does not scale
- High cost
Hiring skilled reviewers or domain experts is expensive - Time-consuming process
Manual review slows down development and iteration cycles - Limited coverage
Only a small portion of outputs can realistically be reviewed - Inconsistent judgments
Different evaluators may rate the same output differently - Growing output volume
AI systems generate thousands or millions of responses daily
Why this matters
Relying only on human evaluation leads to:
- Slower product development
- Gaps in quality control
- Inconsistent evaluation standards
- Difficulty scaling AI systems in production
What this means for AI reliability
Human evaluation is useful for:
- Initial testing
- High-risk use cases
- Fine-tuning models
But it cannot:
- Monitor systems continuously
- Evaluate outputs at scale
- Ensure consistent performance over time
Key takeaway
Human evaluation improves quality, but it cannot support large-scale AI systems alone.
Scalable AI requires automated evaluation and continuous monitoring.
Real-world example
A company deploying a customer support chatbot generates thousands of responses daily.
Manually reviewing each response is not feasible, leading to:
- Missed errors
- Inconsistent quality
- Delayed improvements
FAQs
Why is human evaluation important in AI?
It provides high-quality, contextual feedback that automated systems may miss.
Can human evaluation be replaced completely?
No. It should be combined with automated evaluation for best results.
What is the main limitation of human evaluation?
It cannot scale with the volume and speed of AI-generated outputs.
How can AI evaluation be scaled?
By combining human review with automated evaluation systems and continuous monitoring.
CTA
Scale AI evaluation without manual bottlenecks
Explore the AI Reliability Whitepaper