

- The Evaluation Blind Spot No One Talks About: AI Reliability
- What is AI Reliability?
- Phases of AI Evaluation, and Why Each One Broke
- The 7 Root Causes of AI Production Failures
- SLM-as-a-Judge vs. LLM-as-a-Judge: What Actually Works
- Workflow-Level Evaluation: The Shift CTOs Are Making
- How LLUMO AI’s Eval360™ Closes the Production Gap
- Head-to-Head: All Evaluation Approaches Compared
- What Comes Next: Agentic AI & Self-Healing Systems
- FAQ: Questions We Get Every Week
The Evaluation Blind Spot No One Talks About: AI Reliability
AI reliability is the ability of an AI system to produce accurate, consistent, and trustworthy outputs across real-world conditions, not just in controlled tests. Most AI systems fail in production because they are evaluated on static benchmarks, not live inputs. LLUMO AI’s Eval360™ provides continuous evaluation, hallucination detection, and root-cause analysis to close this gap.
“OpenAI’s own research confirms this, their 2025 paper found that hallucinations persist because training procedures reward guessing over admitting uncertainty. LLUMO AI addresses this at the output layer through real-time evaluation.”
Here is a scenario that plays out in enterprise teams every week ensuring the AI reliability of systems has become a paramount concern. You spend three months building an LLM-powered workflow. It scores 94% on your internal benchmark. Your QA team signs off. You push to production.
Six weeks later, a client emails you a screenshot of your AI confidently citing a policy that does not exist.
|
“We didn’t have a reliability problem. We had a measurement problem. We were measuring the wrong thing and calling it done.” Pattern observed across 100+ LLUMO AI enterprise deployments, 2024 |
The problem is not that your team built something bad. The problem is that the entire industry has been measuring AI correctness at the output layer, while production failures happen at the workflow layer. True AI reliability means understanding all the transformations, dependencies, and handoffs that shape model behavior in production.
| THE EVALUATION BLIND SPOT The evaluation blind spot is the gap between what standard AI testing measures (final output correctness on curated inputs) and what actually determines production reliability: workflow correctness across dynamic, real-world inputs at scale. Most enterprises are optimizing for the wrong signal. |
What is AI Reliability?
As highlighted by Stanford Human-Centered AI Institute, reliability is emerging as a core dimension of AI system evaluation alongside performance and safety.
Think about the last time you asked an AI a question and got a completely wrong answer, but it sounded totally confident. Frustrating, right? That’s exactly what AI reliability tries to fix.
In simple terms, AI reliability means you can trust an AI to do what it’s supposed to do — consistently, correctly, and without surprise failures. It’s not just about being smart. It’s about being dependably smart, every single time.
Why Should You Care?
Imagine using an AI tool to help with medical advice, financial decisions, or legal documents. If it gives you the right answer 80% of the time, what about the other 20%? That gap is where reliability matters most.
Reliable AI isn’t a luxury. It’s a necessity
AI systems are increasingly used in:
1. Legal drafting
2. Healthcare decision support
3. Financial analysis
4. Autonomous agents
Failures in these systems are not theoretical, they have real-world consequences.
A widely cited case involved lawyers submitting fabricated legal citations generated by AI, demonstrating how hallucinations can directly impact professional workflows (reported in multiple legal analyses and Nature commentary on generative AI risks).
Every Phases of AI evaluation solved the previous generation’s problem and created a new one.
Phases of AI Evaluation, and Why Each One Broke
Phase 1: Rule-Based Systems: The Illusion of Control
Deterministic rules made evaluation trivial. Fully interpretable. Fully auditable. But rules cannot encode language, context, or ambiguity.
| Cannot handle language tasks at scale. |
Phase 2: Benchmark-Driven Evaluation: The Goodhart’s Law Problem
GLUE, MMLU, HumanEval enabled apples-to-apples model comparison. Then models learned to overfit to benchmarks. Research on dataset leakage (arXiv) confirms this is systematic: models optimize for the metric, not the underlying capability. A 94% benchmark score can mask a 28% real-world hallucination rate.
Benchmark score ≠ production reliability. |
Phase 3: Human Evaluation: Right Instinct, Wrong Scale
Human raters introduced judgment benchmarks cannot capture. But at 10,000 production queries per hour, human evaluation is economically impossible. Inter-rater agreement on complex tasks is often below 70%.
Cannot scale to production volume. |
Phase 4: LLM-as-a-Judge: Scale Without Accuracy
Using a frontier LLM to evaluate another LLM brought scale back but introduced confidence bias. Research from arXiv (2024) shows LLM judges agree with incorrect outputs when phrased confidently, regardless of factual accuracy. An LLM judge cannot reliably catch hallucinations in a model trained on similar data.
| Bias propagation. Agrees with confidently-wrong answers. |
Phase 5: Observability Tools: Watching the Patient Die
Logging platforms and trace dashboards gave teams visibility into AI failures after they occurred. Valuable but fundamentally reactive. Observability tells you your AI failed. It does not tell you where in the reasoning chain it broke, why, or how to prevent recurrence.
Post-failure detection only. No root cause. No prevention. |
The 7 Root Causes of AI Production Failures
When a CTO asks “why is our AI hallucinating in production?”, the honest answer is usually a stack of compounding structural issues that standard evaluation never surfaces.
1. LLMs Are Probability Machines, Not Fact Machines
This is not a bug, it is architecture. Transformer-based LLMs generate the statistically most likely next token. When they encounter a knowledge gap, they do not abstain; they generate the most plausible-sounding completion. Every enterprise deployment inherits this, regardless of fine-tuning.
2. No Ground Truth Exists at Scale
In legal, financial, and medical domains, the “correct” answer requires domain expertise to verify. Automated evaluation without domain calibration measures the wrong signal. As Nature commentary on generative AI risks confirms, ground truth ambiguity is a primary bottleneck in enterprise AI evaluation.
3. Your Metrics Measure Fluency, Not Truthfulness
BLEU, ROUGE, cosine similarity, the standard metrics score linguistic quality. They do not score factual accuracy, risk, or compliance. An AI that writes beautifully incorrect legal briefs scores well on these metrics. Stanford HAI identifies metric misalignment as a primary driver of production failures.
4. Static Evaluation, Dynamic Reality
Benchmarks are frozen snapshots. Production traffic is a live organism, noisy, domain-shifting, and adversarial. A model tuned for your QA dataset will encounter inputs in production that look nothing like its evaluation set.
5. No Feedback Loops: Mistakes Repeat
Most evaluation systems measure outputs and stop. They do not route failure signals back to prevent recurrence. The same categories of failures appear week after week.
6. Explainability Gaps Slow Everything Down
When a failure occurs, how long does it take your team to answer: “Where exactly in the workflow did this break?” If the answer is days, you have an explainability gap that compounds operational risk in regulated industries.
7. Agentic Workflows Amplify Every Error
A single-step LLM failure is recoverable. A multi-step agentic workflow failure, where a reasoning error in step two corrupts every subsequent step is catastrophic and invisible to output-level evaluation.
| If your current evaluation stack does not address all seven of these root causes, you are not measuring reliability, you are measuring the absence of the most obvious failures. That is a very different thing. |
SLM-as-a-Judge vs. LLM-as-a-Judge: What Actually Works

The LLM-as-a-Judge approach seemed like the obvious solution: use a powerful frontier model to evaluate other models’ outputs at scale. It works, until it doesn’t. The failure modes are specific and reproducible.
| SLM-AS-A-JUDGE An SLM-as-a-Judge is a Small Language Model trained specifically on evaluation tasks not on general-purpose text generation. Because it is optimized for judgment rather than generation, it does not inherit the confidence bias or hallucination tendencies of frontier LLMs used as judges. LLUMO AI’s Eval360™ is an SLM-as-a-Judge trained on over 2 million real-world AI evaluations, the largest evaluation-specific training dataset in the category. |
Workflow-Level Evaluation: The Shift CTOs Are Making
Output-level evaluation asks: Was the final answer correct?
Workflow-level evaluation asks: Which step in the reasoning chain failed, which tool call returned bad data, and where did retrieval surface the wrong context?
These are fundamentally different questions and only one of them helps you prevent the next failure.
What Workflow-Level Evaluation Covers
- Retrieval Quality: Did the RAG pipeline surface the correct context? Was the retrieved chunk relevant, current, and complete?
- Reasoning Chain Integrity: Did each intermediate reasoning step follow logically? Did the model maintain factual consistency across a multi-step response?
- Tool Call Accuracy: For agentic systems, did the model call the right tools with the right parameters? Did it handle tool errors gracefully?
- Prompt Sensitivity Analysis: Does the system produce consistent outputs across semantically equivalent prompt variations?
- Business Objective Alignment: Does the output serve the business goal? Compliance, tone, completeness, and domain standards are not captured by accuracy metrics.
Engineering teams using workflow-level evaluation identify failure root causes in hours rather than weeks and ship AI to production with 90% less debugging time. The investment is in evaluation architecture; the return is in deployment velocity. |
How LLUMO AI’s Eval360™ Closes the Production Gap
LLUMO AI was built on a single conviction: The AI industry needs a reliability layer, not just another monitoring dashboard, not another benchmark, and not a repurposed frontier model called a “judge.” Eval360™ is that reliability layer.
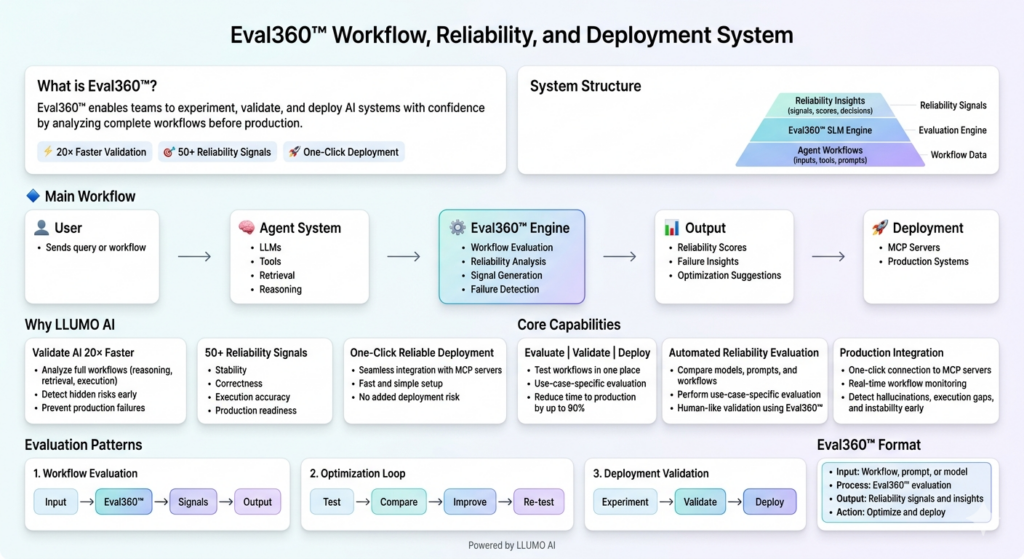
|
“Eval360™ transforms evaluation from a passive measurement system into an active AI reliability engine, one that does not just tell you what broke, but prevents the next breakage.” LLUMO AI |
| Capability | What It Does | Why It Matters |
| SLM-as-a-Judge Engine | Evaluates using a model trained on 2M+ real-world evaluations | No confidence bias; domain-calibrated; no hallucination inheritance |
| Workflow-Level Analysis | Evaluates retrieval, reasoning, tool calls not just final output | Catches failures before they reach users; enables surgical fixes |
| Root Cause Analysis | Identifies which workflow step failed and why | Cuts incident response from weeks to hours |
| Custom Metrics Engine | Aligns evaluation to business goals and compliance requirements | Stops measuring fluency when you need to measure risk and impact |
| Real-Time Monitoring | Continuous evaluation across production traffic | Catches AI reliability drift before users encounter it |
| Closed Feedback Loops | Routes evaluation insights back into system improvement | Compounding reliability gains; mistakes stop repeating |
Head-to-Head: All Evaluation Approaches Compared
| Approach | Scalable? | Root Cause? | Workflow-Level? | Feedback Loop? | AI Reliability |
| Benchmarks | Yes | No | No | No | Low |
| Human Evaluation | No | Partial | No | No | Medium |
| LLM-as-a-Judge | Yes | No | No | No | Medium |
| Observability Tools | Yes | No | No | No | Medium |
| LLUMO AI / Eval360™ | Yes | Yes | Yes | Yes | Very High |
The pattern is unambiguous: every alternative solves for scale or accuracy, never both, and never at the workflow level with root cause analysis and feedback loops. That combination is the gap LLUMO AI was built to close.
What Comes Next: Agentic AI & Self-Healing Systems
Agentic AI Raises the Reliability Stakes Exponentially
The shift from single-turn chatbots to multi-step autonomous agents changes the AI reliability calculus entirely. In a five-step agentic workflow, a failure at step two does not produce one wrong output, it corrupts everything downstream. Only workflow-level, step-by-step reliability evaluation can catch this.
Continuous Evaluation Pipelines Replace QA Cycles
Static pre-deployment testing gates will give way to continuous evaluation pipelines that assess AI behavior against real production traffic in real time. Evaluation becomes living infrastructure not a pre-launch checklist you run once and forget.
Self-Healing AI Systems Will Close the Loop Automatically
The next generation of reliable AI systems will not just detect failures and alert engineering teams. They will diagnose root causes, generate remediation recommendations, and in some cases initiate fixes autonomously, mirroring how mature infrastructure engineering handles system failures today.
| TAKEAWAY: The question is not whether your AI will fail in production, every AI system does. The question is whether your evaluation architecture catches those failures before users do, tells you exactly why they happened, and prevents recurrence automatically. That is the new standard . |
FAQ: Questions We Get Every Week
Q: Why does our AI pass every test but still fail in production?
AI systems fail in production because testing uses controlled, curated inputs while production involves dynamic, unpredictable real-world queries. A model can score 94% on a benchmark and still hallucinate 28% of the time in production. Without continuous evaluation and monitoring, failures go undetected until they cause real business impact.
Q: What is the difference between SLM-as-a-Judge and LLM-as-a-Judge?
LLM-as-a-Judge uses a general-purpose frontier model trained primarily to generate text to evaluate other models’ outputs. It suffers from confidence bias, inherits training data biases, and is not calibrated to domain-specific correctness standards. SLM-as-a-Judge uses a small model trained specifically on evaluation tasks, making it more accurate, faster, cheaper, and free from generative biases. LLUMO AI’s Eval360™ is trained on 2M+ real-world evaluations.
Q: What is workflow-level AI evaluation?
Workflow-level evaluation assesses every step of an AI system’s execution chain, retrieval quality, reasoning chain integrity, tool call accuracy, prompt handling, and output-to-business-objective alignment rather than just the final output. It catches failures at the source, not at the symptom.
Q: How can we reduce AI hallucinations without slowing deployment?
Five changes reduce hallucinations without adding friction:
(1) shift from output-level to workflow-level evaluation;
(2) replace generic LLM judges with domain-trained SLM judges;
(3) add root cause analysis so you fix the right thing immediately;
(4) implement real-time monitoring with early degradation detection;
(5) close the feedback loop so evaluation insights automatically improve future behavior.
Q: How is AI reliability different from AI observability?
AI observability tells you what happened after a failure, logs and traces showing that your system produced a bad output. AI reliability prevents failures from reaching users through pre-deployment workflow evaluation, root cause analysis, and closed feedback loops. Observability is reactive. AI Reliability is preventive.
Related reading from the AI Reliability Series:
→ Why do AI models hallucinate?
→ Why are LLM benchmarks unreliable?
→ Why prompt engineering doesn’t solve AI reliability?
→ Why AI systems fail silently?
| Stop Deploying AI You Can’t Trust.Book a 30-minute technical session with LLUMO AI. We will run Eval360™ on a sample of your production traffic and show you exactly where your reliability gaps are before your users find them: https://app.llumo.ai/signin |